Introduction
For 32 years now, the venerable HTTP protocol has been at the heart of the Web. This protocol enables “resources” (anything that can be named can be a resource, but these are often documents) to be retrieved from a server using their unique identifier: their URL.
Since 1991, the Web has exploded in popularity, to the point where it can now be considered one of the backbones of our societies. With this craze, new uses have emerged, and numerous functionalities have been added to the “web platform” to enable them.
One of the most popular of these new uses is the real-time updating of resources displayed to users of a website or web application. Users expect, for example, to be able to see in real-time the modifications made to a shared document (collaborative editing à la Google Docs), the stock status of a highly sought-after product sold on an e-commerce site, or the replies to messages they have posted on an online discussion forum.
So you download a “resource” (the shared document, product sheet, or forum message) from a server, and it’s displayed by your browser. But what happens if this resource is modified or enhanced by its author or by another user after you’ve downloaded it? As a web developer, how can you notify users consulting this resource that it has changed? Or better still, can you send the changes made to this resource directly to users, so that their browsers can display them in real time?
Unfortunately, even the most recent versions of HTTP (HTTP/3, HTTP/2) don’t natively offer this functionality.
Over time, several techniques and protocols have been developed to maintain persistent connections between client and server: Comet (1996, now obsolete), Server-Sent Events (2004), WebSocket (2008), and WebTransport (still under development). All these techniques have different advantages and disadvantages, but they are all relatively low-level, not specifically designed to send updates to a resource previously retrieved by HTTP, and require considerable effort on the part of developers to use them to meet this use case.
Still, one protocol stands out from the crowd: WebSub (2018, successor to Google’s PubSubHubbub). WebSub is a system for subscribing to updates made to web resources via a webhooks mechanism. WebSub suffers from one major limitation, however: it is intended for server-to-server communication only. The server that wishes to subscribe to updates made to a resource published by another server exposes a URL that will be called in POST by the server controlling the resource. A browser is a client, not a server, so it can’t expose URLs that will receive these updates.
IETF 118 Prague
For some time now, there has been renewed interest in developing a standard (or several, see below) enabling clients to receive updates on resources published by servers.
Three proposed standards have been submitted to the IETF in recent years: Mercure (full disclosure: I’m the main author of this spec developed by Les-Tilleuls.coop), Braid, and PREP. Braid and PREP have been discussed at IETF Conference 118 in Prague a few weeks ago.
The three proposals have many features in common: high-level mechanisms for subscribing to updates from an HTTP resource, the ability to transfer only the changes to be applied to the resource (patches) rather than the complete resource, the ability to negotiate in which format updates should be sent, and the ability to retrieve only updates made from a given version of a resource already available to the client (reconciliation).
These similarities show that several independent teams have found similar solutions to the same need. This demonstrates that the emergence of a standard (or several) is both feasible and necessary.
However, the three approaches also have their differences, which we will now describe in detail.
Braid
Let’s start with the most ambitious of the three proposals: Braid.
Braid is much more than a simple pub/sub mechanism like WebSub, Mercure, or PREP. It’s an HTTP extension that provides a complete framework for synchronizing states between server and client.
Like Mercure and PREP, Braid offers a mechanism enabling web browsers to subscribe to changes made to resources, but Braid goes much further by also offering a complete version management system, a patch format, and a merge system supporting numerous conflict management algorithms (OT, CRDT, etc.).
In this article, we’ll concentrate on subscriptions. Here’s an example of how to send new versions of a resource (here /chat) via Braid, taken from the Internet-Draft:
HTTP/1.1 209 Subscription
Subscribe:
Version: "ej4lhb9z78"
Parents: "oakwn5b8qh", "uc9zwhw7mf"
Content-Type: application/json
Merge-Type: sync9
Content-Length: 64
[{"text": "Hi, everyone!",
"author": {"link": "/user/tommy"}}]
Version: "g09ur8z74r"
Parents: "ej4lhb9z78"
Content-Type: application/json
Merge-Type: sync9
Patches: 1
Content-Length: 53
Content-Range: json .messages[1:1]
[{"text": "Yo!",
"author": {"link": "/user/yobot"}]
Version: "2bcbi84nsp"
Parents: "g09ur8z74r"
Content-Type: application/json
Merge-Type: sync9
Patches: 1
Content-Length: 58
Content-Range: json .messages[2:2]
[{"text": "Hi, Tommy!",
"author": {"link": "/user/sal"}}]
Version: "up12vyc5ib"
Parents: "2bcbi84nsp"
Content-Type: application/json
Merge-Type: sync9
Patches: 1
Content-Length: 288
Content-Type: application/json-patch+json
[
{"op": "test", "path": "/a/b/c", "value": "foo"},
{"op": "remove", "path": "/a/b/c"},
{"op": "add", "path": "/a/b/c", "value": []},
{"op": "replace", "path": "/a/b/c", "value": 42},
{"op": "move", "from": "/a/b", "path": "/a/d"},
{"op": "copy", "from": "/a/d", "path": "/a/d/e"}
]In broad terms, Braid proposes to introduce a new HTTP request header, “Subscribe”, and an HTTP response code “209 Subscription”. When a subscription is created, a persistent connection between the client and the server must be maintained, and the server will send changes made to the resource as a patch in this connection.
As already mentioned, Braid goes much further and specifies how to pass version information or merge algorithms to be used.
It should be noted that Braid will work best with the relatively extensive adaptation of existing servers to be able to support these new functionalities, as well as the implementation of new APIs in browsers (which can be polyfilled).
Although the approach seems relatively straightforward in HTTP/1.1, things get more complicated when you want to take advantage of HTTP’s advanced features. For example, Braid requires that the size of each update (Content-Length header) be known before it is sent, otherwise, the client won’t know when the content of the current update stops and the headers of the next one start. This constraint prevents streaming at the update level, which can be a problem when sending large updates (a mitigation to this problem is to send a set of small patches instead of a big one, but this comes with an overhead).
Similarly, unlike HTTP/1.1, which is a text-based protocol, HTTP/2 and HTTP/3 are now binary protocols, allowing for several optimizations such as header deduplication and compression. Taking advantage of these optimizations with Braid will probably require extensions dedicated to HTTP/2+ binary encodings, and significant adaptation of web servers, proxies, browsers, and other HTTP clients.
Nevertheless, the work done by the Braid team is impressive, and could well be the real-time future of the Web!
PREP
PREP, for Per Resource Events Protocol, is an alternative proposal from Rahul Gupta, a person involved in the Solid community (a specification designed to enable the creation of decentralized web applications originating from the creator of the Web itself). PREP was created by Rahul to allow clients to be notified when a resource hosted by a Solid Pod (a server storing user data) is modified.
I’ve written about Solid on this blog before and even implemented the client side of the protocol in PHP. It’s great news to see the people involved in the Solid community taking part in discussions to standardize a common protocol for publishing resource updates.
PREP is less ambitious than Braid (the Solid specification covers some of the needs covered by Braid) and focuses on subscribing to updates. Excerpt from Internet-Draft:
GET /foo HTTP/1.1
Host: example.org
Authorization: DPoP <token>
DPoP: <proof>
Last-Event-ID: *
Accept-Encoding: gzip
Accept-Events: PREP; accept=message/rfc822; accept-encoding=identity
HTTP/1.1 200 OK
Vary: Accept-Events, Last-Event-ID
Accept-Events: PREP; accept=message/rfc822
Events: protocol=PREP, status=200, vary=accept-encoding
Last-Modified: Sat, 1 April 2023 10:11:12 GMT
Transfer-Encoding: chunked
ETag: 1234abcd
Content-Type: multipart/digest; boundary=next-message
--next-message
Content-Type: message/rfc822
<message>
--next-message--We can see that the approach proposed by PREP is quite similar to the one proposed by Braid. Rather than specifying the size of the forthcoming update in a Content-Length header, PREP relies on the multipart/digest media type (defined in RFC 1341 dating from… 1992 and updated in RFC 2046 from… 1995, these RFC have initially been designed for the email protocols, and are still in use today), which allows multiple messages to be embedded in a main message. As you can see, each update becomes a message embedded in the main response.
Reusing multipart also has the advantage of solving the streaming problem (no need to calculate message size before sending), but seems a bit of a fiddle, and is less “elegant”/idiomatic than the solution proposed by Braid.
The client indicates that it supports PREP-type updates via a new header: Accept-Events.
Interestingly, this new header allows the client to negotiate with the server which updates the protocol to use. For example, a server supporting both PREP and Mercure could send updates using either protocol, depending on what the client requests via Accept-Events.
Braid and PREP could be the future of the real-time Web…
As we’ve seen, both Braid and PREP are tackling a problem that has existed since the beginning of the Web, and that’s a very good thing. We have to keep in mind that Braid and PREP aren’t finalized protocols, will continue to evolve, and ideally will be merged before becoming an internet standard. Eventually, if these initiatives are successful, the web platform could have a native, elegant, and idiomatic mechanism for sending resource publications.
I proposed to the authors of Braid and PREP an approach very similar to theirs, but even more efficient and semantically correct.
Instead of sending a special response that itself contains several nested responses (updates), a similar but more efficient (and in my opinion even more elegant) approach could be to take inspiration from the 103 Early Hints code, which is now supported by Chrome. It’s not widely known, but the HTTP specification allows multiple responses to be sent in reply to a request, thanks to the 1XX status code class. The 103 Early Hints, which I’ve written about extensively on this blog, allow the server to send special responses to the client before the final response, to tell the client – for example – which JavaScript and CSS files it can start downloading while the server is generating the final response.
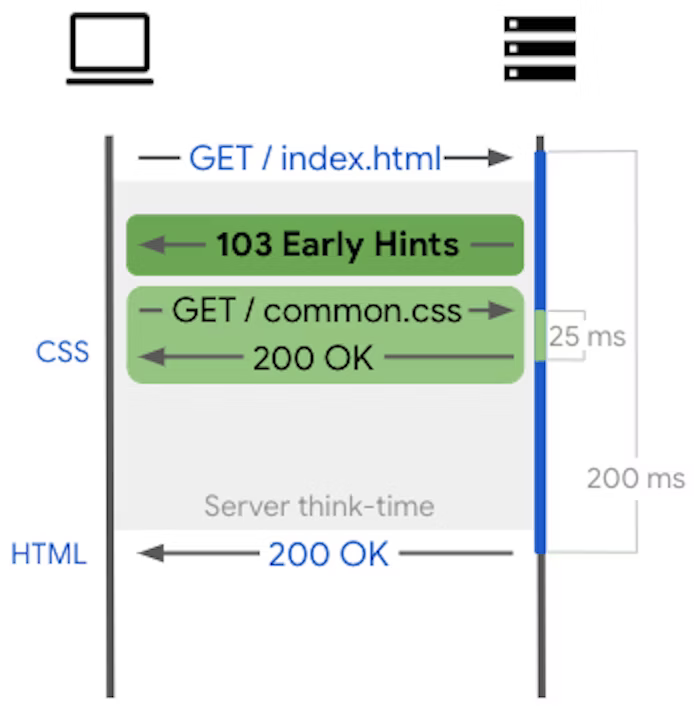
Similarly, we could imagine a new status class, 7XX, which would allow responses to be sent after the main response:
Request:
GET /my-resource
Response:
709 Subscription
Content-Type: application/ld+json
{
"baz": "qux",
"foo": "bar"
}
709 Subscription
Content-Type: application/json-patch+json
[
{ "op": "replace", "path": "/baz", "value": "boo" },
{ "op": "add", "path": "/hello", "value": ["world"] },
{ "op": "remove", "path": "/foo" }
]Of course, this will be hard to make the existing HTTP/1.1 ecosystem compatible with this, but both Braid and PREP suffer from severe limitations when used with HTTP/1.1 anyway (see below). On the other hand, it would be quite possible to create an extension to HTTP/2 and HTTP/3 that would add a new setting and new frames to the binary protocols to enable this approach. In addition, all optimizations such as header compression will be supported.
…when Mercure focuses on the present
However, all three proposals share a common problem: a persistent connection must be established between the client and the server for each resource. Updates will then be pushed into this connection.
The problem with this approach is that it’s extremely difficult to deploy in today’s Web, and is likely to remain so for a very long time.
Indeed, many technologies such as PHP (around 80% of websites), serverless technologies such as Amazon Lambda and Cloudflare Worker, or the venerable CGI and FastCGI (which are also still widely used in production) are not designed and generally don’t allow persistent connections to be maintained between the server and the client. All these stacks have a relatively short timeout which makes it impossible, or at least very difficult, to deploy these solutions.
We could imagine creating reverse proxies to be placed in front of the applications using these stacks that will maintain these persistent connections, but they don’t yet exist and will represent a considerable amount of work to implement if they ever are. Secondly, they would severely limit the appeal of solutions like serverless. Finally, it would mean that all traffic would have to pass through these reverse proxies, as subscriptions are not limited to a specific URL but can potentially be created from any URL served by the server.
Finally, these approaches will require the adaptation of all existing tools (proxies, WAFs, HTTP clients, etc.) to take into account these new formats, which require reading inside the HTTP request to extract nested responses.
From experience, writing servers that maintain persistent connections is also much more difficult: you have to be very careful about memory leaks, optimize both software and hardware to support very large numbers of parallel connections, etc.
Another problem with these approaches – although less annoying – is that browsers limit the number of persistent connections using HTTP/1.1 to 6 (by default, 100 are available in HTTP/2 and 3, and this number can be negotiated between the client and the server).
The Mercure specification, for its part, was designed from the very beginning to work right out of the box, without requiring major modifications to existing tooling, and with the ability to integrate very easily into serverless, PHP, or (Fast)CGI stacks.
In broad terms, Mercure is a transposition of the WebSub specification we’ve already mentioned, except that it enables web resource updates to be sent over an SSE connection, a persistent connection mechanism that has been supported by all browsers and proxies for a very long time, and which is simple and doesn’t require an SDK or library.
The big difference between WebSub and Mercure on one side, and Braid, PREP, and the like on the other side, is that WebSub and Mercure offer to concentrate all resource updates on a single URL. A “hub”, which may be an external software component running on hardware optimized for this type of use, will multiplex all resource updates onto a single HTTP connection.

Mercure also adds JWT-based authorization management to WebSub, enabling verification that a client is authorized to receive the resource to which it has subscribed, as well as a publishing protocol, enabling the application server to publish a real-time update with a simple POST request to the hub, that could also be useful for Braid or PREP reverse-proxies on top of PHP or serverless apps.
Although Mercure is not yet standardized, the protocol is already battle-tested, used by hundreds of projects in production, has a reference implementation of a Hub, is open source, high-performance, has a very active community, 3,500 stars on GitHub and integrations in numerous languages and frameworks including Python, Java, Dart, Symfony, and Laravel (PHP) or Hotwired (JavaScript).
Towards an upgrade path
To sum up, Braid and PREP offer innovative protocols that provide an elegant, high-performance solution to a problem as old as the Web itself.
Mercure, on the other hand, offers a protocol that, while far less elegant, is still based on the already deployed web standards and – above all – has the advantage of working in production right now.
What if the solution was two protocols? Let’s face it, PHP, serverless and even CGI aren’t going anywhere anytime soon. And even for stacks that enable the creation of persistent connections, we’ve seen that implementing and, above all, managing a large number of persistent connections for potentially all site resources in production applications right now will be no mean feat.
Perhaps the solution to this paradox has already been found by PREP: being able to negotiate the update mechanism to be used (via a header, or an HTTP/2+ parameter as I propose) would allow advanced stacks to use Braid or PREP, and more traditional applications to fallback to Mercure.
The best summary is probably that of Michael Toomim, author of Braid:
“Braid and PREP are designing for deeper changes in HTTP, browsers, servers, and proxies.
Mercure is designed to plug easily into existing browsers, servers, and proxies with minimal core changes.”
So if you need real-time right now, try Mercure!
P.S.: Many thanks to Rahul Gupta and Michael Toomim for their proofreading of this article and for the many exchanges that followed!
The subscribe mechanism on this site doesnt work. I just get errors on various browsers.